by Jennifer Daniel
(This article was originally published on Jennifer’s Substack, January 17, 2023. Republished here with minor revision.)
 In the fall of 2022, the Unicode Technical Committee announced that the 2023 release of the Unicode Standard would be a “dot” release with limited character additions, with the next major release in 2024.
In the fall of 2022, the Unicode Technical Committee announced that the 2023 release of the Unicode Standard would be a “dot” release with limited character additions, with the next major release in 2024. This wasn’t without precedent — COVID slowed
down the release of
Unicode 14.0 in 2020 and the world seemed to survive 😉. Subcommittees
were well prepared and adjusted accordingly, discussing what this meant for
their respective areas of expertise.
For the Emoji Subcommittee (ESC) — the group responsible for defining
the rules, algorithms, and properties necessary to achieve interoperability
between different platforms for those smiley faces that appear on your keyboard
(Shout out 😁🥰🥹🤔🫣🫡😵💫!) — this delay presented an opportunity. Sure, we
were so close to exhaling a sigh of relief (the intake period for Emoji 16.0
proposals had just completed). But upon learning we couldn’t ship any new
codepoints until 2024 we turned our energy towards recommending
new emoji based on existing ones. (These are called
emoji ZWJ
sequences. That's when a combination of multiple emoji display as a
single emoji … like 👩 🏽 +🏭 = 🧑🏽🏭).
When Less is More
An incredibly powerful aspect of written language is that it consists
of a finite number of characters that can "do it all". And yet, as the emoji
ecosystem has matured over time our keyboards have ballooned and emoji
categories are about to hit or have hit a level of saturation. Upon reflecting
on
how
emoji are used, the ESC has entered a new era where the primary way
for emoji to move forward is not merely to add more of them to the Unicode
Standard. Instead, the ESC approves fewer and fewer emoji proposals every year.
But our work is not done. Not by a longshot. Language is fluid and doesn’t
stand still. There is more to do! This “off-cycle” gives us a chance to address
some long-standing major pain points using emoji. The first one that came to
mind: skin-tone.
What is a family?
The encoding of multi-person multi-tone support has matured over the years;
However, the implementation can seem random to the average person: While it’s
true, all people emoji have toned options (with the exception of characters
where you can’t see skin like 🤺) there are … misfits. Some two people emoji
offer tone support ( 🧑🏻❤️🧑🏿) others do not ( 👯). A few non
RGI emoji
render with tone but with no affordance to change one of the two characters (For
example, 🤼🏾♂ renders with skintone on Android but as gold on iOS. WHY. This
is why we standardize these things, people).
And then ... There is the suite of family emoji
(👨👦👨👦👦👨👧👨👧👦👨👧👧👩👦👩👦👦👩👧👩👧👦👩👧👧
👨👨👦👨👨👦👦👨👨👧👨👨👧👦👨👨👧👧👩👩👦👩👩👦👦👩👩👧👩👩👧👦👩👩👧👧👨👩👦👨👩👦👦👨👩👧👨👩👧👦👨👩👧👧👪).
These characters include two people, three people, sometimes four and none of
them have any tone support (!). We seem to have a lot of family emoji and yet
simultaneously not enough.
The 26 “family” emoji can be broken down into four groups:
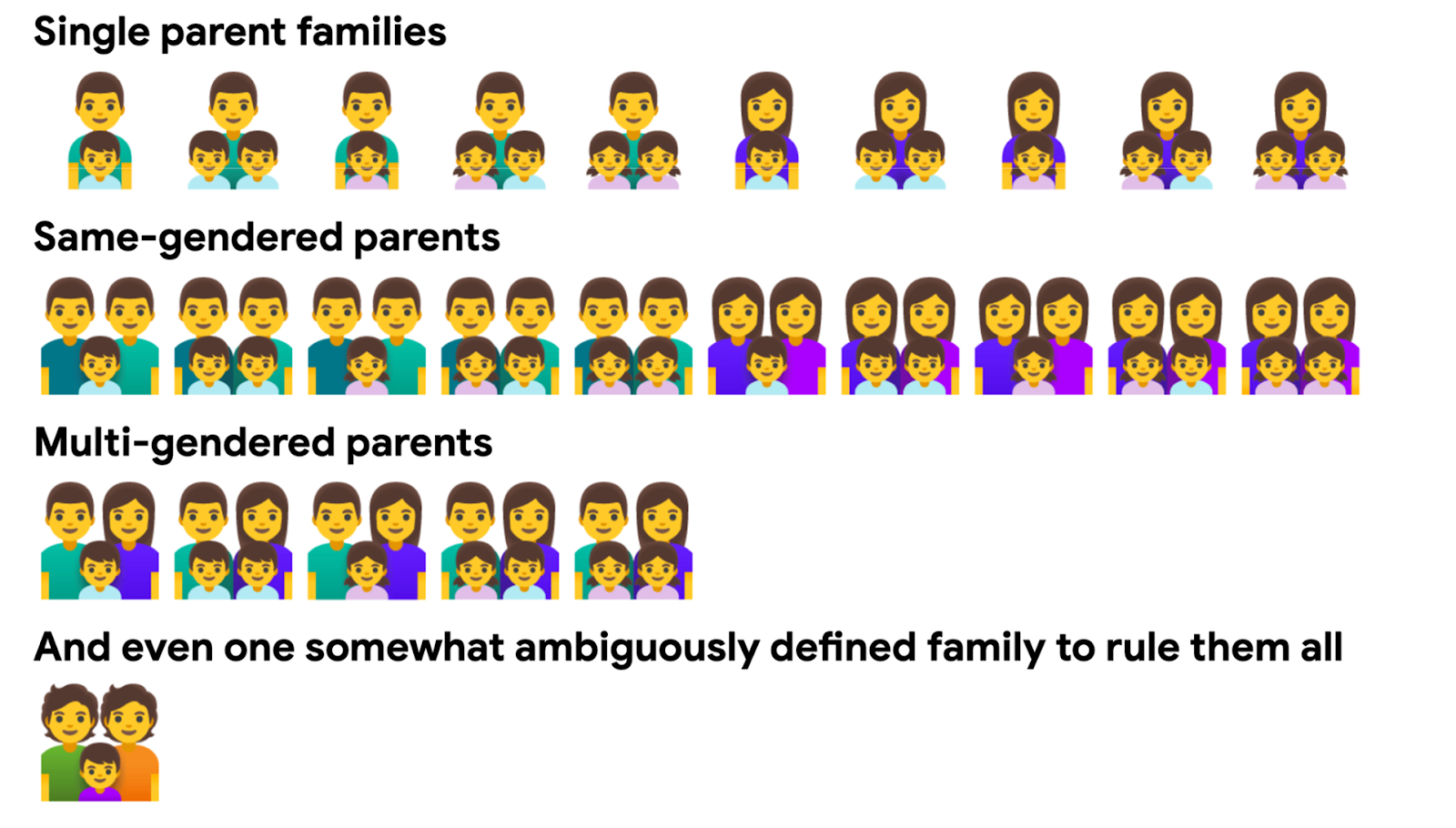
Despite the Unicode Standard containing 26 “family” emoji, each one of these
glyphs is overly prescriptive with regard to delivering on a visual
representation of a family. The inclusion of many permutations of families was
well intentioned. But we can’t list them all, and by listing some of the
combinations, it calls attention to the ones that are excluded.
What even is a family? For some, family is the people you were raised with.
Others have embraced friends as their chosen family. Some families have
children, other families have pets. There are multi-generational families,
mutliracial families and of course many families are any combination of all of
these characteristics and more.
Fortunately, we don’t need to add
7000
variants to your keyboards (even this would fall short of capturing
the breadth of "family" as a concept). Instead we can juxtapose individual emoji
together to capture a concept with some reasonable level of specificity — not
too unlike arranging letters together to create words to convey concepts 😉

For emoji keyboards to advance in creating more intuitive and
personalized experiences the Emoji Subcommittee is recommending a visual
deprecation of the family emoji. This small set of emoji will be
redesigned as part of a
multi-phase effort to “complete the set” of toned variants for the
remaining multi-person emoji. This of course begs the question: when there are
as many families as there are people in the world, is there an effective way at
conveying the concept of “family” without being overly prescriptive in defining
what is and is not a family? Well, thankfully icons can do a lot of heavy
lifting without requiring very much detail.

When is an emoji running for the police or getting chased by them?
Another area the ESC is actively exploring is how the semantics of emoji
sequences can differ when writing directionality changes. Some emoji characters
have semantics that encode implicit directionality but when the string is
mirrored and their meaning may be unintentionally lost or changed.
 Left to Right Emoji Sequence:
Quickly running towards an “exciting” police chase
Left to Right Emoji Sequence:
Quickly running towards an “exciting” police chase
 Right to Left Emoji Sequence:
Running away from the coppers
Right to Left Emoji Sequence:
Running away from the coppers
What, if anything, can we do to aid in ensuring that messages are
meaningfully translated be them tiny pictures or tiny letters? As part of 15.1
we’re proposing a small set of emoji with strong directionality — with an
initial focus on people — to face the opposite direction. Soon you too can run
towards or away from ... excitement.
Emoji 15.1
Given that the intake cycle of emoji proposals for Unicode 16.0 ended
last July, the Emoji Subcommittee has also decided to temporarily delay the
intake of Unicode Version 17.0 proposals until April 2024. Fortunately, you
won’t have to wait until then to get new emoji.
(Note: I know
it sounds like I’m talking about the past and future simultaneously ... the emoji
lifecycle is looooong and as a result overlaps with multiple releases. Expect a
future blog post about the
Emoji
15.0 candidates landing early this year (Shout out goose, pink heart,
and pushing hands). I’ve been holding off writing about this set until you can
actually see them on your phones but given that we’re already talking about 2024
maybe it’s time I dust that blog post off).

Anyways, among the list of Emoji 15.1 recommendations for 2024 includes 578
characters (most of them the candidates described above to support
directionality). The list also includes a few humble additions including a
broken chain, a lime, a non-poisonous mushroom, a nodding and shaking face, and
a phoenix bird. Each one of these leverages a unique valid ZWJ sequence of
emoji so while they look like atomic characters made of a single codepoint they
are composed of two or more codepoints.

Broken chain is the result of a 🔗💥 ZWJ and contains a variety of meanings,
such as freedom, breaking a cycle, or perhaps a broken url ;-). Nodding face and
shaking face are composed of arrows to imply movement in a still image (🙂↔️)
and (🙂↕️). Oh, and of course there is a phoenix rising from the ashes (🐦🔥),
an ancient metaphor that captures the zeitgeist of today.
The Unicode Technical Committee (UTC) will review the required documents at its first meeting of 2023 in January – and if these candidates move forward,
you can expect an update from the UTC later this Spring and Summer.
Adopt a Character and Support Unicode’s Mission
Looking to give that special someone a special something?
Or maybe something to treat yourself?
🕉️💗🏎️🐨🔥🚀爱₿♜🍀
Adopt a character or emoji to give it the attention it deserves,
while also supporting Unicode’s mission to ensure everyone can
communicate in their own languages across all devices.
Each adoption includes a digital badge and certificate that you can proudly display!
Have fun and support a good cause
You can also donate funds or
gift stock

![[image]](https://www.unicode.org/announcements/cldr42-annc-postalHorn144.png) The Unicode CLDR v45
is now available and has been integrated into version 75 of ICU. The
CLDR v45 release page
has information on accessing the data, reviewing charts of the changes, and
— importantly —
Migration issues.
The Unicode CLDR v45
is now available and has been integrated into version 75 of ICU. The
CLDR v45 release page
has information on accessing the data, reviewing charts of the changes, and
— importantly —
Migration issues.![[image]](https://www.unicode.org/announcements/cldr40-alpha-annc.png) The Unicode
The Unicode  The Unicode Consortium is pleased to announce that
The Unicode Consortium is pleased to announce that
 “The rewards have been much greater than I could have ever imagined.”
“The rewards have been much greater than I could have ever imagined.” Unicode Consortium is excited to welcome Cathy Wissink to the Board
effective immediately. Cathy is a 30-year veteran of the global tech
industry. Most of her career was spent at Microsoft, with her early tenure
devoted to internationalization support for Windows. She then spent 15
years working focused on global government and regulatory affairs. In her
most recent role at Microsoft, Cathy managed a part of Microsoft’s
standards portfolio supporting regulatory needs in forums like ISO/IEC
JTC1, CEN/CENELEC, NIST, and also led Microsoft’s product certification
process for China.
Unicode Consortium is excited to welcome Cathy Wissink to the Board
effective immediately. Cathy is a 30-year veteran of the global tech
industry. Most of her career was spent at Microsoft, with her early tenure
devoted to internationalization support for Windows. She then spent 15
years working focused on global government and regulatory affairs. In her
most recent role at Microsoft, Cathy managed a part of Microsoft’s
standards portfolio supporting regulatory needs in forums like ISO/IEC
JTC1, CEN/CENELEC, NIST, and also led Microsoft’s product certification
process for China.

